Dynamic Nagios Configuration For AWS Services Using Ansible
 In our last Ansible post I covered how you can leverage Ansible to perform configuration management tasks on AWS. In this our final post in the planned series on Ansible, I will cover how to build a playbook that can be used to (re)build your Nagios configuration any time your AWS environment changes instead of having to manually update Nagios to reflect new or removed instances running monitored services.
In our last Ansible post I covered how you can leverage Ansible to perform configuration management tasks on AWS. In this our final post in the planned series on Ansible, I will cover how to build a playbook that can be used to (re)build your Nagios configuration any time your AWS environment changes instead of having to manually update Nagios to reflect new or removed instances running monitored services.
Here at KISS, our go-to environment availability monitoring tool is Nagios. While it definitely is not the flashiest of tools, it does one thing and does it well...monitoring. One of its most attractive features is its simplicity and ability to be extended to do anything you may want. I say anything because to date there has not ever been a case where I needed to monitor a system or service that was not possible either out of the box or by writing a simple plugin script. However, one of the downsides is if you have a fast changing environment, which is typical in the cloud, it becomes a constant battle to ensure your monitoring configuration matches your current state of affairs. As we began using Ansible for more and more tasks, I decided it was time to see what could be done to have a single command to re-build an entire Nagios configuration using EC2 tags so as to not have to add and remove configuration manually every time a change occurs.
All of the following is also located in our Github repository found here: https://github.com/kissit/kiss-ops/tree/master/ansible
Overview
In this post, we'll be building off of the Ansible and AWS concepts already covered in previous posts. We'll assume you already have the Ansible EC2 plugin installed and configured. Furthermore, the goal of this post is not to explain how to configure Nagios, and while configuration examples will be provided specific to our example we'll assume you are familiar enough with Nagios to fill in the blanks. Our example will be based off of the following AWS configuration, as usual all based on CentOS 6.x:
- An existing EC2 instance named web1 that will provide web services
- An existing EC2 instance named redis1 that will provide redis services
Once the environment is built and our task is ready, we will add one more of each of the above and rebuild our configuration to verify the process works.
Nagios server requirements
For our example we already have a Nagios environment setup on another AWS instance. It is nothing out of the ordinary, installed from the standard yum packages. In addition to that we also need the NRPE plugin to be installed since we use that tool to monitor various aspects of the client system, to install this we do the following:
yum install nagios-plugins-nrpeWe also make use of this plugin for monitoring Redis. We installed it as so:
wget https://raw.githubusercontent.com/willixix/WL-NagiosPlugins/master/check_redis.pl -O /usr/lib64/nagios/plugins/check_redis.pl chmod 755 /usr/lib64/nagios/plugins/check_redis.pl
And the following command definitions are required in addition to the default configuration. We place this in /etc/nagios/conf.d/commands.cfg:
# 'check_nrpe' command definition
define command{
command_name check_nrpe
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}
# 'check_redis' command definition
define command {
command_name check_redis
command_line $USER1$/check_redis.pl -H $HOSTADDRESS$
}
# 'check_http' command definition.
# Note this may be present in the default commands.cfg but we want the ability to pass in a URI so redefine our own
define command{
command_name check_http
command_line $USER1$/check_http -I $HOSTADDRESS$ -u $ARG1$
}
We also need to create directories for our hosts and hostgroup configuration files we'll be creating below:
mkdir -p /etc/nagios/hosts /etc/nagios/hostgroups
And finally we need to tell Nagios to look in those directories for configuration files, to do so we add the following two lines to the file /etc/nagios/nagios.cfg.
cfg_dir=/etc/nagios/hosts cfg_dir=/etc/nagios/hostgroups
Nagios client requirements
As mentioned above we typically use the NRPE daemon to monitor various aspects of the clients like CPU, memory, disk space, etc. Essentially this tool allows us to run nagios plugins on the client via the check_nrpe server side plugin and retrieve the results via that protocol. It is by no means required but will be used in our example. A typical installation would go as follows:
yum install nrpe nagios-plugins-all bc
As with the server, we will use some extra plugins on the client. In this case we need one to monitor the real memory usage of the system and you can install it as follows:
wget https://raw.githubusercontent.com/kissit/kiss-ops/master/monitoring/nagios/plugins/check_mem.sh -O /usr/lib64/nagios/plugins/check_mem.sh chmod 755 /usr/lib64/nagios/plugins/check_mem.sh
And of course we need our standard NRPE client configuration which define the commands that it will respond to. We place this in /etc/nrpe.d/base.cfg:
command[check_load]=/usr/lib64/nagios/plugins/check_load -w 15,10,5 -c 30,25,20 command[check_root]=/usr/lib64/nagios/plugins/check_disk -w 20% -c 10% -p / command[check_zombie_procs]=/usr/lib64/nagios/plugins/check_procs -w 5 -c 10 -s Z command[check_total_procs]=/usr/lib64/nagios/plugins/check_procs -w 150 -c 200 command[check_swap]=/usr/lib64/nagios/plugins/check_swap -w 50% -c 20% command[check_mem]=/usr/lib64/nagios/plugins/check_mem.sh 90 95
Ansible to the rescue!
Now, lets get into what this post is really about, how to use ansible to build the rest of our server config for the environment. Once again, we'll rely on our ability to define tags on our EC2 instances to know what configurations to apply. This means we need to set the tag nagios_hostgroups on each of our classes of instances that contain a comma separated list of Nagios host groups that will be defined in our configuration:
- Web instances: nagios_hostgroups == nrpe,web
- Redis instances: nagios_hostgroups == nrpe,redis
Here is a screen shot showing an example of how this tag should look on your EC2 instance:
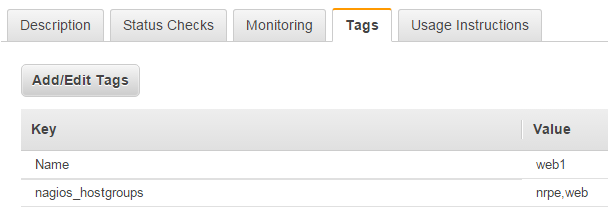
Next we'll use our best practices directory structure from our existing ansible project for this work. Here I create a high level playbook for this task in our main ansible project directory named nagios.yml with the following:
---
- hosts: x.x.x.x
sudo: yes
gather_facts: False
roles:
- nagios
vars:
current_hosts: []
The important part to note here is that unlike most playbooks where we are running a task against all matched hosts, in this case we only want to run our task on our Nagios server. So here you should replace x.x.x.x with the public IP of your nagios server . The inventory data will only be used to provide the details to feed into the Nagios configuration on that server.
Next, we want to define the main task that will build the configuration. Since we've defined this to use the role nagios we will create our task as file roles/nagios/main.yml:
## Playbook to auto configure hosts and checks in our nagios server
---
- name: "Get list of previous host configs"
shell: ls -1 /etc/nagios/hosts/ | sed -e 's/\.[^\.]*$//'
register: previous_hosts
- name: "Create a cfg file for each host"
template: src="linux_server.cfg" dest="/etc/nagios/hosts/{{ item }}.cfg"
with_items: groups['ec2']
when: hostvars[item].ec2_state == 'running' and hostvars[item].ec2_tag_nagios_hostgroups is defined
- name: "Remove stale hosts"
file: path="/etc/nagios/hosts/{{ item }}.cfg" state=absent
with_items: previous_hosts.stdout_lines
when: item not in groups['ec2'] or hostvars[item].ec2_tag_nagios_hostgroups is undefined
- name: "Update our hostgroup configurations"
template: src="hostgroup_{{ item }}.cfg" dest="/usr/local/nagios/etc/hostgroups/{{ item }}.cfg"
with_items:
- nrpe
- web
- redis
- name: "Restart Nagios"
service: name=nagios state=restarted
Here is a little explanation of what each step does:
- Step 1: Here we get a list of all of the existing host configuration files from the nagios server. In our case they are located in /etc/nagios/hosts. We save this list in a variable for use in a following step.
- Step 2: Here is where we create our configuration file for each instance with the nagios_hostgroups tag. This will write a separate configuration file base on our linux_server.cfg template for each instance in our inventory that has the nagios_hostgroups tag defined. This allows us to simply not set that tag on any instances that we don't want to monitor for whatever reason.
- Step 3: Here we remove any "stale" host configuration files by finding which entries from step #1 were not found in step #2. This is how we handle removing hosts from our configuration once they are removed from AWS.
- Step 4: Here is where we write out our Host Group configuration files that say what checks are run for a given group. You can easily add more here as needed.
- Step 5: Restart the nagios service to reflect the changes
There were some templates mentioned above, so lets review those. First is the individual host configuration which will be added as roles/nagios/templates/linux_server.cfg.
# {{ ansible_managed }} define host { use linux-server host_name {{ hostvars[item].ec2_tag_Name }} alias {{ hostvars[item].ec2_tag_Name }} address {{ hostvars[item].ec2_private_ip_address }} hostgroups {{ hostvars[item].ec2_tag_nagios_hostgroups }} }
The above is a pretty standard Nagios host definition. We simply use the Ansible variables as needed to include the information for each host we process. The hostgroups line is where we include the comma separated list from the nagios_hostgroups tag. So not only do we use that tag to trigger the main system host monitoring, we also use it to say what to monitor in terms of services.
The next 3 templates correspond to the step #4 where we use with_items to loop over each hostgroup name to set its configuration. Note that these technically could be static files on the nagios server, but I chose to include them in this process so that changes to them could easily be pushed out using the same process as when we add/remove instances. First is the nrpe hostgroup in file roles/nagios/templates/hostgroup_nrpe.cfg.
# {{ ansible_managed }} define hostgroup{ hostgroup_name nrpe; alias NRPE Checks; } define service{ use generic-service hostgroup_name nrpe service_description Root Filesystem check_command check_nrpe!check_root } define service{ use generic-service hostgroup_name nrpe service_description Memory Usage check_command check_nrpe!check_mem } define service{ use generic-service hostgroup_name nrpe service_description Load Avg check_command check_nrpe!check_load }
This is a typical Nagios host group configuration that defines the host group and adds 3 checks to it; a check of the root file system space utilization, a check of used memory, and a check of the load average.
Next is the web hostgroup which is defined in the file roles/nagios/templates/hostgroup_web.cfg.
# {{ ansible_managed }}
define hostgroup{
hostgroup_name web;
alias Web servers;
}
define service{
use generic-service
hostgroup_name web
service_description Web Server
check_command check_http!/check.html
}
Finally the redis hostgroup which is defined in the file roles/nagios/templates/hostgroup_redis.cfg.
# {{ ansible_managed }}
define hostgroup{
hostgroup_name redis;
alias Redis Servers;
}
define service{
use generic-service
hostgroup_name redis
service_description Redis Server
check_command check_redis
}
Putting it to use
Finally, its time to run our new playbook to build our configuration. On our Ansible control system, lets go ahead and run our new playbook using our EC2 inventory as follows. I've included the output for reference:
ansible-playbook nagios.yml -i inventory/ec2.py -u centos -s PLAY [52.25.210.113] ********************************************************** TASK: [nagios | Get list of previous host configs] **************************** changed: [52.25.210.113] TASK: [nagios | Create a cfg file for each host] ****************************** changed: [52.25.210.113] => (item=52.36.74.57) skipping: [52.25.210.113] => (item=52.25.210.113) changed: [52.25.210.113] => (item=52.36.142.4) TASK: [nagios | Remove stale hosts] ******************************************* skipping: [52.25.210.113] TASK: [nagios | Update our hostgroup configurations] ************************** changed: [52.25.210.113] => (item=nrpe) changed: [52.25.210.113] => (item=web) changed: [52.25.210.113] => (item=redis) TASK: [nagios | Restart Nagios] *********************************************** changed: [52.25.210.113]
Success! After some time for the checks to complete the nagios web portal shows both hosts being monitored for the nrpe services and the additional services monitored on web1 and redis1 respectively:
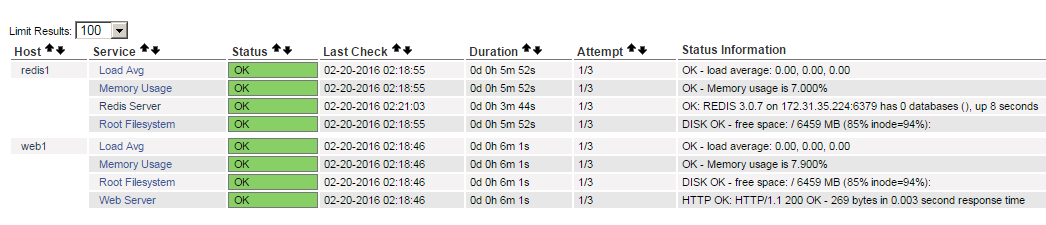
Now, lets add two more instances, web2 and redis2, each with the corresponding tags and rerun the playbook:
ansible-playbook nagios.yml -i inventory/ec2.py -u centos -s PLAY [52.25.210.113] ********************************************************** TASK: [nagios | Get list of previous host configs] **************************** changed: [52.25.210.113] TASK: [nagios | Create a cfg file for each host] ****************************** ok: [52.25.210.113] => (item=52.36.74.57) changed: [52.25.210.113] => (item=52.34.245.226) changed: [52.25.210.113] => (item=52.36.54.36) skipping: [52.25.210.113] => (item=52.25.210.113) ok: [52.25.210.113] => (item=52.36.142.4) TASK: [nagios | Remove stale hosts] ******************************************* skipping: [52.25.210.113] => (item=52.36.142.4) skipping: [52.25.210.113] => (item=52.36.74.57) TASK: [nagios | Update our hostgroup configurations] ************************** ok: [52.25.210.113] => (item=nrpe) ok: [52.25.210.113] => (item=web) ok: [52.25.210.113] => (item=redis) TASK: [nagios | Restart Nagios] *********************************************** changed: [52.25.210.113]
Note in the output that it now processed two new hosts. I I go back to the nagios portal, again after the checks are all run for the first time, we are now monitoring the new hosts without having to manually change any of the configuration on the nagios server.
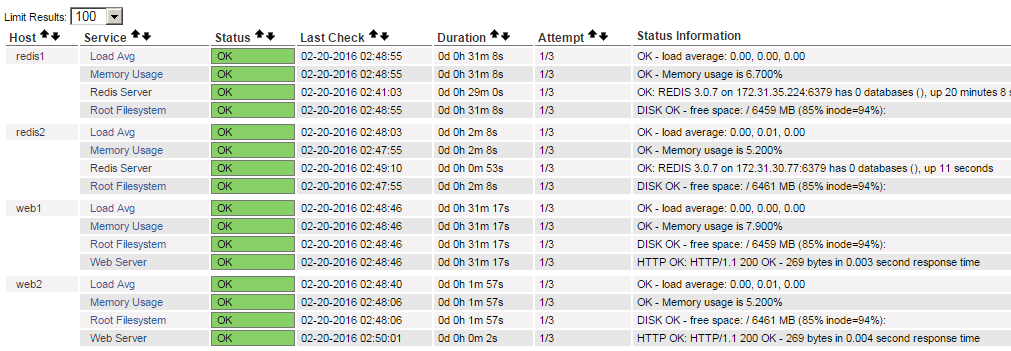
Finally, lets stop (or terminate) the first two instances, web1 and redis1 and rerun our playbook once again:
ansible-playbook nagios.yml -i inventory/ec2.py -u centos -s PLAY [52.25.210.113] ********************************************************** TASK: [nagios | Get list of previous host configs] **************************** changed: [52.25.210.113] TASK: [nagios | Create a cfg file for each host] ****************************** ok: [52.25.210.113] => (item=52.34.245.226) skipping: [52.25.210.113] => (item=52.25.117.105) ok: [52.25.210.113] => (item=52.36.54.36) skipping: [52.25.210.113] => (item=54.201.51.39) skipping: [52.25.210.113] => (item=52.25.210.113) TASK: [nagios | Remove stale hosts] ******************************************* skipping: [52.25.210.113] => (item=52.34.245.226) changed: [52.25.210.113] => (item=52.36.142.4) skipping: [52.25.210.113] => (item=52.36.54.36) changed: [52.25.210.113] => (item=52.36.74.57) TASK: [nagios | Update our hostgroup configurations] ************************** ok: [52.25.210.113] => (item=nrpe) ok: [52.25.210.113] => (item=web) ok: [52.25.210.113] => (item=redis) TASK: [nagios | Restart Nagios] *********************************************** changed: [52.25.210.113]
Note in the output that in this case we removed the two configuration files for the hosts we just removed. Now when I check the nagios portal I only see my two newer instances. I won't bother showing you another screen shot I think you get the point by now :-)
Conclusion
While it took a while to get here, we now have an Ansible playbook that can be re-run any time you change your AWS environment in a way that affects your nagios configuration to sync those changes to your nagios configuration. I hope you can quickly see the power of this, you can easily add additional host groups or additional types of nagios configuration as needed. Thanks again for taking the time to review our work and as always, please don't hesitate to contact us with any questions or comments regarding this post.